
データベース正規化の導入
データベース正規化は、リレーショナルデータベース設計における基本的な技術であり、データの重複を最小限に抑え、データの整合性を確保し、挿入、更新、削除などのデータ操作中に異常が発生しないようにするためのものです。1970年代にエドガー・F・コッドが彼のリレーショナルモデルの一部として開発したこの手法は、正規形と呼ばれるルールに基づいて、データベースをテーブルに構造化し、それらの間の関係を定義することを含みます。これらの正規形に従うことで、データベースはより効率的でスケーラブルになり、時間の経過とともに保守しやすくなります。
本質的に、正規化は、データの混乱した集まりから、洗練され、論理的な構造へとデータベースを変換します。これは、単純なアプリケーションから複雑なエンタープライズデータベースまで、幅広く使用されており、不要な重複を避けつつ、正確な照会やレポート作成を可能にするデータの保存方法を保証しています。
データベース正規化の主要な概念
正規化は、データの重複や依存関係の問題を特定の種類に対処するために、前の段階を基盤として次の段階へと進む「正規形」と呼ばれる一連の段階を経ます。以下に、主な正規形を例を交えて説明します:
1. 第一正規形(1NF)
- 定義:テーブルが1NFにあるとは、すべての値が原子的(分割できない)であり、列内に繰り返しグループや配列がないことを意味します。各行と各列の交点には単一の値が含まれており、各レコードは一意でなければなりません。
- 重要なルール:多値属性を解消するために、別々の行またはテーブルを作成する。
- 例:顧客注文のためのテーブルを考え、列「Items」に「Apple, Banana, Orange」という値が含まれているとします。1NFを達成するためには、これを個別の行に分割します。つまり、注文ごとに各アイテムごとに1行ずつ作成します。これにより、1つのアイテムを更新するとリスト全体に影響が出るといった問題を防ぐことができます。
2. 第二正規形(2NF)
- 定義:テーブルが2NFにあるとは、1NFにあり、かつすべての非キー属性が主キー全体に完全関数従属している(部分的依存がない)ことを意味します。
- 重要なルール:複数の行に適用されるデータのサブセットを、別々のテーブルに移動し、外部キーでリンクすることで削除する。
- 例:OrderID(主キー)、CustomerID、CustomerName、Itemという列を持つテーブルにおいて、CustomerNameはCustomerIDにのみ依存している(部分的依存)。2NFに正規化するためには、CustomerIDとCustomerNameを別々のCustomersテーブルに移動し、OrdersテーブルでCustomerIDを外部キーとして参照する。
3. 第三正規形(3NF)
- 定義:テーブルが3NFにあるとは、2NFにあり、かつ推移的依存がない(非キー属性が他の非キー属性に依存しない)ことを意味します。
- 重要なルール:すべての属性が、他の属性を経由せずに主キーに直接依存していることを確認する。
- 例:EmployeeID、DepartmentID、DepartmentLocationを持つEmployeesテーブルにおいて、DepartmentLocationはDepartmentIDに依存している(推移的依存)。DepartmentIDとDepartmentLocationを持つDepartmentsテーブルを作成し、外部キーでリンクすることで正規化する。
高次の正規形
- ボイス・コッド正規形(BCNF):3NFよりも厳格なバージョンで、すべての決定要因が候補キーであることを要求します。重複する候補キーを扱う際に有用です。
- 第四正規化形 (4NF): 多値依存関係に対処し、同じテーブル内に独立した多値の事実が存在しないことを保証する。
- 第五正規化形 (5NF): 連結依存関係に対処し、複雑な関係から生じる冗長性を排除するために、テーブルをさらに分割する。
これらの正規化形は累積的である。より高いレベルを達成するには、低いレベルを満たす必要がある。3NFは多くの実用的なデータベースにとって十分であるが、複雑なデータ関係を持つ状況では、より高い正規化形が適用される。
データベース正規化が面倒な理由
利点があるものの、正規化は特に大規模または複雑なデータセットでは労力が大きく、誤りが生じやすいプロセスである。以下が、それがしばしば面倒とされる理由である:
- 依存関係の手動分析: 機能的依存、部分的依存、推移的依存を特定するには、データ関係の深い分析が必要である。これは要件の確認、冗長性の発見、異常の予測といった作業を含み、専門知識と時間が求められる。
- 反復的なテーブル分割: 各正規化形では、テーブルの再構成、キーの追加、関係の再定義が必要になることがある。例えば、1NFから3NFへ移行する際には、テーブルの分割を複数回繰り返す必要があり、テーブルや結合の数が増加し、クエリが複雑化する可能性がある。
- 正規化とパフォーマンスのバランス: 過剰な正規化は結合が多すぎることになり、読み取り操作の速度を低下させる。設計者はパフォーマンス向上のため、しばしば戦略的に非正規化を行う必要があり、意思決定の層が追加される。
- ドキュメント作成とテスト: 変更を手動でドキュメント化し、異常(例:null値なしではデータを追加できない挿入異常)をテストすることは時間のかかる作業である。この段階での誤りは、データの整合性の欠如を引き起こす可能性がある。
- スケーラビリティの問題: 演化するデータベースでは、スキーマ変更後の再正規化は繰り返し行われやすく、リスクが伴い、生産システムに影響を与える可能性がある。
要するに、正規化の面倒さは、手動的で反復的な性質に起因し、データ整合性の問題を避けるために正確さが求められ、同時に使いやすさを維持する必要があるためである。
Visual ParadigmのDBModeler AIツールがデータベース正規化をどのように簡素化するか
図解および設計ツールのリーディングプロバイダーであるVisual Paradigmは、AIを活用したデータベース設計ツール「DBModeler AI」を発表した。このツールは、自然言語による記述を完全に正規化されたデータベーススキーマに変換することで、正規化プロセスを自動化・簡素化する。これにより、手作業の負担が軽減され、開発が加速する。
主な機能とワークフロー
DBModeler AIのワークフローはインタラクティブでガイド付きであり、初心者から専門家まで誰でも使いやすい。
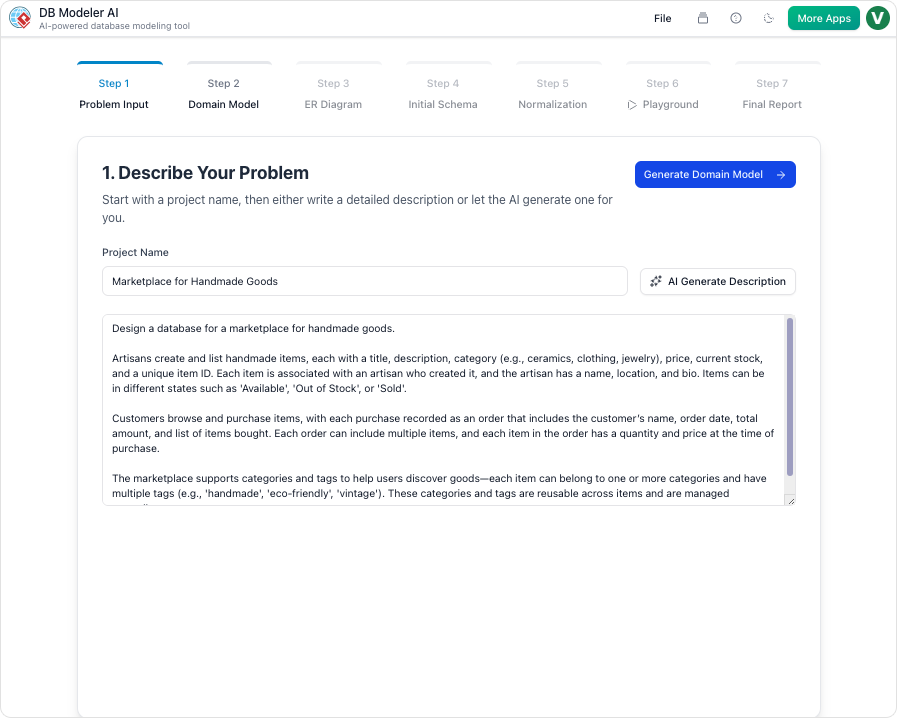
- 自然言語による入力要件: 自然言語でデータベースの要件を記述し始めよう。例:「顧客注文を追跡するシステムで、製品、数量、配送詳細を含む。」
- ドメインクラス図とER図の生成: AIは即座に編集可能なPlantUMLドメインクラス図と詳細なエンティティ関係(ER)図を生成し、エンティティ、属性、関係を可視化する。
- 自動正規化: スキーマを1NFから3NFまで段階的に正規化し、各変更の根拠と説明をステップバイステップで提供する。この教育的側面により、冗長性や推移的依存の削除など、調整の理由を理解しやすくなる。
- SQLの生成とテスト: PostgreSQL互換のSQL DDLスクリプトを生成する。AIが生成したサンプルデータで初期化された組み込みライブSQLプレイグラウンドにより、データベース環境を構築せずにクエリを即座にテストできる。
- リアルタイム編集とエクスポート: 図面、SQL、ドキュメントをインタラクティブに編集できます。共有や統合のために、すべてをPDFまたはJSON形式でエクスポートできます。
依存関係の分析とテーブルの再構成を自動化することで、DBModeler AIは多くの手間を省き、デザイナーが再設計からではなく、仕上げの段階に集中できるようにします。視覚的なフィードバック、AI駆動のインサイト、迅速なプロトタイピングを通じてプロセスを簡素化し、設計時間を大幅に短縮します。
DBModeler AIのデータベース正規化における活用事例
DBModeler AIは多様な専門家や状況に対応できる汎用性を持ちます:
- プロジェクトの立ち上げを行う開発者: 副業プロジェクトやプロトタイプの場合、開発者は要件から迅速に正規化されたスキーマを生成し、SQLをテストして、手動での図面作成なしに反復作業が可能です。
- 学生および学習者: 説明付きのインタラクティブな正規化は、実践的な例を通じて関数的依存性などの概念を理解するのに役立つ教育ツールです。
- ビジネスニーズを技術的要件に変換するプロダクトマネージャー: 高レベルのビジネス要件を技術的なER図やスキーマに変換し、ステークホルダーと技術チームの間のギャップを埋めます。
- 複雑さを扱うシステムアーキテクト: 企業向けシステムの複雑なデータモデルをプロトタイピングし、関係性を文書化し、実装前に正規化を確実にします。
実際のアプリケーション、たとえばECプラットフォームやCRMシステムでは、スケーラブルな効率的な設計を保証し、長期的な保守コストを削減します。
おすすめ:Visual ParadigmのDBModeler AIを選ぶ理由
データベース設計に取り組んでいる場合、私は強くおすすめします:Visual ParadigmのDBModeler AI正規化をスムーズにする画期的なツールです。AI支援によるアプローチは時間の節約だけでなく、正確性と学習の質を向上させ、面倒な作業を扱いやすくします。Visual Paradigmのプラットフォームを通じて利用可能で、効率的で協働的なツールを求めているチームに最適です。詳細は公式サイトをご覧いただき、機能を確認し、すぐに使い始めましょう。
DBModeler AIとは何ですか?
DBModeler AIは、ウェブベースのツールで、データベース要件を完全に正規化され、本番環境対応のデータベーススキーマに変換します。ユーザーをを通じて、そしてテストを行います。
コア機能
| 機能 | 概要 |
|---|---|
| AI駆動型アーキテクチャ | 自然言語を使用して、アプリのアイデアを詳細な技術的要求事項に翻訳します。 |
| 多段階の図示 | 編集可能なPlantUMLドメインクラス図およびER図を生成します。 |
| 段階的正規化 | 冗長性の除去の説明とともに、スキーマを1NF、2NF、3NFへと段階的に進化させます。 |
| ライブSQLプレイグラウンド | ブラウザ内SQLクライアントとAI生成のサンプルデータを使用して、スキーマを即座にテストします。 |
| 完全なコントロール | 図、SQL、ドキュメントのリアルタイム編集を可能にし、PDF/JSON形式でエクスポートできます。 |
ステップバイステップのワークフロー
| ステップ | アクション |
|---|---|
| 1. 問題の入力 | アプリケーションを平易な英語で説明してください。AIがそれを技術的要求事項に拡張します。 |
| 2. ドメインクラス図 | 編集可能なPlantUML図で、高レベルのオブジェクト/属性を可視化します。 |
| 3. ER図 | ドメインモデルを、キーと関係を含むデータベース固有のER図に変換します。 |
| 4. 初期スキーマ | ER図をPostgreSQL互換のSQL DDLステートメントに翻訳します。 |
| 5. インテリジェントな正規化 | AIによる変更の根拠を伴い、スキーマを1NFから3NFへ最適化します。 |
| 6. インタラクティブなプレイグラウンド | 現実的なデータで初期化されたブラウザ内SQLクライアントで、スキーマを実験します。 |
| 7. 最終レポートとエクスポート | 図、ドキュメント、SQLスクリプトをPDF/JSON形式でエクスポートします。 |
対象ユースケース
- 開発者: プロジェクトのデータベース層を素早く構築・検証できます。
- 学生: 相互作用的に関係データモデル化と正規化を学べます。
- プロダクトマネージャー: ビジネス要件を技術仕様書/ER図に変換できます。
- システムアーキテクト: 複雑なデータ関係を視覚的にプロトタイピングおよび文書化できます。
最高の結果を得るためのヒント
- .
- : 正規化の際にAIの説明を学習ツールとして活用してください。
- 本番エクスポートの前に。
なぜ際立っているのか
DBModeler AI 自動化とユーザー制御を組み合わせることで、特に.
お探しのニーズに合わせたをご検討いただけますか?