
ソフトウェアアーキテクチャは、複雑さを管理するためにしばしば再帰パターンに依存する。コンポジットデザインパターンは、クライアントが個々のオブジェクトとオブジェクトの構成を一貫して扱えるようにする構造的解決策である。洗練された一方で、このアプローチは特定のリスクをもたらす。複合構造が失敗すると、その影響はアプリケーション全体に波及する可能性がある。このガイドは、複合階層内の設計上の欠陥を識別・隔離・解決するための体系的なアプローチを提供する。
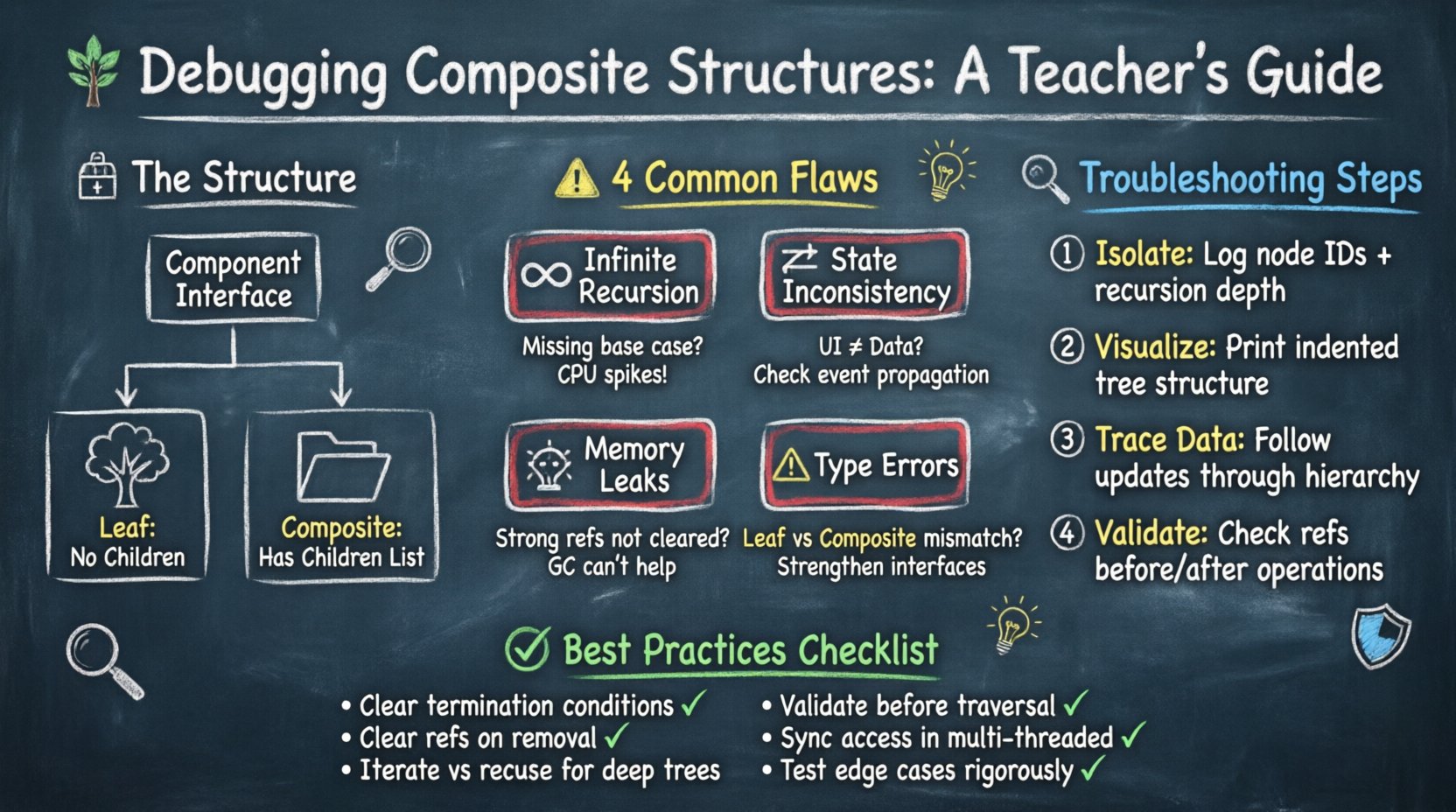
コンポジット構造の理解 🌳
コンポジット構造は、要素を木構造のような階層に整理する。このモデルには主に3つの役割がある:
- コンポーネント:階層内のすべてのオブジェクトに対するインターフェース。子コンポーネントへのアクセスおよび管理を行うためのメソッドを宣言する。
- リーフ:木の末端。リーフは子を持たず、基本的な振る舞いを備えたコンポーネントインターフェースを実装する。
- コンポジット:コンテナ。子コンポーネントのリストを保持し、操作をそれらに委譲する。
この構造は、ユーザーインターフェース、ファイルシステム、組織図において基本的である。しかし、再帰的な性質が潜在的な落とし穴を生む。デバッグには、データがこれらの層をどのように流れているかを理解することが求められる。
一般的な設計上の欠陥とその症状 🚩
コンポジット構造におけるエラーは、しばしば微妙な形で現れる。パフォーマンスの低下、メモリリーク、特定の条件下でのみ発生する論理エラーとして現れることがある。以下は開発および保守中に最も頻繁に遭遇する問題である。
1. 無限再帰ループ
メソッドが木を走査する際には、明確な終了条件が必要である。子コンポーネントが親をチェックせずに参照している場合、または走査ロジックにベースケースが欠けていると、システムは無限ループに入ってしまう。これは通常、アプリケーションのクラッシュやメインスレッドの停止を引き起こす。
- 症状:アプリケーションがフリーズする、またはCPU使用率が100%に急上昇する。
- 根本原因:nullチェックの欠如、または子リスト内の循環参照。
2. 状態の不整合
コンポジット構造はしばしば共有状態に依存する。親が子に基づいて状態を更新する一方で、子が親に通知せずに独立して状態を更新すると、階層が非同期状態になる。これは、視覚状態がデータ状態と一致しなければならないUIレンダリングにおいてよく見られる。
- 症状:UI要素が古くなった情報を表示する、またはデータモデルと視覚的表現が矛盾する。
- 根本原因:イベントの伝播の欠如、または状態更新中の競合状態。
3. 強参照によるメモリリーク
コンポーネントはしばしば子に対して強参照を持つ。親が削除された後も子が親への参照を保持していると、ガベージコレクションはメモリを回収できなくなる。逆に、子が親への参照を保持していると、リーフを分離しても親が無駄な負荷を抱え続けることになる。
- 症状:アプリケーションのメモリ使用量が時間とともに安定的に増加し、解放されない。
- 根本原因: コンポーネントの削除やクリーンアップ中に参照をクリアしないこと。
4. タイプセーフティ違反
動的型付け環境、あるいは継承を伴う静的型付けシステムにおいて、リーフをコンポジットが期待される場所に渡す(あるいはその逆)と、実行時エラーが発生する可能性がある。インターフェースが厳密でない場合、クライアントが特定のノード型にのみ存在するメソッドを呼び出す可能性がある。
- 症状:特定のノード上でメソッドを呼び出した際に実行時例外が発生する。
- 根本原因:弱いインターフェース契約、または不適切なキャスト。
トラブルシューティング手法 🔍
これらの問題を解決するには、厳密なアプローチが必要である。理解していないものを修復することはできない。以下のステップは、コンポジット構造の問題を診断する論理的なプロセスを示している。
ステップ1:障害発生ポイントを特定する
コードを変更する前に、論理が破綻する正確な場所を特定する。ログ出力を用いて実行パスを追跡する。スタックトレースだけに頼らないこと。スタックトレースはオブジェクトグラフの状態を示さない可能性がある。
- 再帰メソッドの開始時に現在のノードIDを出力する。
- 再帰の深さをログに記録し、ループを早期に検出する。
- 操作の前後で親子リストの状態を確認する。
ステップ2:階層を可視化する
テキストログだけでは複雑な木構造には不十分である。構造を可視化することで、構造的な異常を明らかにする。多くのツールでは、オブジェクトグラフを図として描画できる。ツールが利用できない場合は、インデントで深さを表すように、ツリー構造を出力するヘルパーメソッドを記述する。
可視化のための例のロジック:
- ルートノードを走査する。
- 各子ノードに対して、深さに比例したインデントを付けて出力する。
- ノードタイプ(リーフまたはコンポジット)を表示する。
- 重複するノードIDや欠落している子ノードがないか確認する。
ステップ3:データフローを分析する
データが構造を通じてどのように移動するかを追跡する。すべての更新が正しく伝播しているか?すべての読み取りが正しい値を取得しているか?不整合は、コンシューマーがライターが終了する前に読み取ってしまう非同期更新によって生じることが多い。
- 書き込み操作中にロックメカニズムが存在するか確認する。
- 読み取り操作が書き込み操作を不必要にブロックしないようにする。
- 操作の順序が依存関係グラフと一致しているか確認する。
一般的な問題参照表 📊
この表を用いて、症状を潜在的な原因や解決策に迅速にマッピングする。
| 症状 | 潜在的な原因 | 診断アクション |
|---|---|---|
| アプリケーションが応答停止する | 無限再帰 | デバッグモードで最大深さ制限を設定する。 |
| メモリ使用量が増加する | クリアされていない参照 | ノード削除時にオブジェクト参照を確認する。 |
| UIの描画が正しくない | 状態の非同期化 | 状態変更に対してイベントリスナーを実装する。 |
| ヌルポインタ例外 | 子要素のチェックが欠落している | 子リストにアクセスする前にガードを追加する。 |
| 集約における論理エラー | 不適切な蓄積論理 | リーフノードの基本ケース値を確認する。 |
深掘り:特定の欠陥シナリオ 🔬
これらの欠陥のメカニズムを理解することは予防に役立つ。具体的なシナリオを詳しく検討しよう。
シナリオA:分離された親の問題
複合体が子要素を削除すると、子要素はしばしば親への参照を保持したままになる。その後、その子要素が別の親に再接続された場合、古い親に通知を送り続けてしまう可能性がある。これにより、孤立したリスナーと論理エラーが発生する。
- 修正: 以下のことを確実にする:
removeメソッドが子要素の親参照を明示的にnullに設定する。 - 修正:親との関係が子要素のライフサイクルにおいて厳密に必要でない場合は、弱参照を使用する。
シナリオB:集約ループ
以下の操作のようにcalculateTotalはしばしばすべての子要素からの値を合計する。この計算中に子要素が動的に追加された場合、ループは新しい子要素を処理し、その結果さらに別の子要素が追加される可能性があり、動的な拡張を引き起こす。
- 修正:反復処理の前に子リストのスナップショットを作成する。
- 修正:反復中に構造の変更をサポートしないイテレータを使用する。
シナリオC:スレッドセーフのギャップ
コンポジット構造は、UIスレッドやマルチスレッド環境で頻繁に使用される。2つのスレッドが同時に子リストを変更すると、内部の配列やリスト構造が破損する可能性がある。これにより、要素がスキップされたり、重複処理が行われたりする。
- 修正:子コレクションへのアクセスを同期する。
- 修正:子リストにスレッドセーフなデータ構造を使用する。
- 修正:構造の変更を反復処理のロジックから分離する。
安定性のためのリファクタリング 🏗️
欠陥が特定されたら、再発を防ぐためにリファクタリングが必要である。目的は、コンポジットパターンのシンプルさを損なわずに構造を堅牢にする点にある。
1. インターフェース契約の強制
コンポーネントインターフェースが利用可能な操作を厳密に定義していることを確認する。コンポジットの内部実装詳細をクライアントに公開しないようにする。これにより、エラーの発生領域を制限できる。
- 子リストをプライベートにし、制御されたアクセスメソッドのみを提供する。
- 可能な限り、子リストの不変ビューを使用する。
2. 検証フックの実装
子要素を追加または削除する前に、状態を検証する。子要素はすでに存在するか?親は有効か?構造は不変条件を満たしているか?
- 次のようなメソッドを追加:
validateAdd(child)を挿入前に実行するメソッド。 - 検証フェーズ中に循環参照を確認する。
3. 反復処理ロジックの分離
木を反復するロジックとそれを変更するロジックを分離する。これにより、反復中に構造を変更するリスクを低減できる。反復処理の複雑さは、外部でビジターパターンを使用して処理する。
- 反復メソッドを読み取り専用に保つ。
- 変更ロジックを専用のマネージャクラスに移動する。
パフォーマンスに関する考慮事項 🚀
コンポジット構造は成長するにつれて高コストになることがある。デバッグは正しさだけでなく、効率性にも関係する。大きな木構造は、深い再帰処理中にスタックオーバーフローを引き起こす可能性がある。
1. スタックの深さ制限
再帰的なメソッドはスタック領域を消費します。木の深さがシステムのスタック制限を超えると、アプリケーションがクラッシュします。深い階層構造では、この問題を解決することが重要です。
- 明示的なスタックデータ構造を使用して、再帰的なアルゴリズムを反復的なものに変換する。
- 木の深さにハード制限を設け、その制限を超えるノードは拒否する。
2. ライズ評価
すべての子ノードを即座に読み込むと、過剰なメモリを消費する可能性があります。大きな枝に対しては、遅延読み込みを検討してください。アクセスされたときだけ子ノードをインスタンス化する。
- 実際の子インスタンスの代わりに、ファクトリ関数を保存する。
- 子ノードの初期化は、特定のメソッドが初めて呼び出されたときのみ行う。
3. バッチ操作
ノードを1つずつ追加または削除すると、各操作ごとに検証とイベントの発火が発生します。一括変更の場合は、操作をバッチ処理する。
- 次の
bulkAddメソッドは、処理中に通知を無効化する。 - バッチ処理が完了した後に、1つのイベントを発火する。
コンポジット構造のテスト 🧪
コンポジット構造のユニットテストは、個々のコンポーネントと階層全体の両方をカバーしなければならない。深い再帰的なバグに対しては、統合テストにのみ頼るのは不十分である。
1. 基本ケースのテスト
リーフコンポーネントが正しく動作することを確認する。これは再帰の終了条件である。基本ケースが壊れると、全体の構造が失敗する。
- リーフの操作が子ノードにアクセスしようとしていないことを確認する。
- リーフの状態変更が隔離されていることを確認する。
2. 再帰ケースのテスト
コンポジットが子ノードに正しく委譲していることを確認する。これにより、パターンが意図した通りに動作していることが保証される。
- 操作回数が子ノードの操作回数の合計と一致していることを確認する。
- 階層の深さが正しく維持されていることを確認する。
3. 端末ケースのテスト
空の木、単一のノード、そして深くネストされた構造は、バグが隠れる場所である。
- 空のコンポジットに対する操作をテストする。
- コンポジットから最後の子ノードを削除する操作をテストする。
- 子ノードを失うことなく、親を交換する操作をテストする。
4. ストレステスト
メモリリークやパフォーマンスのボトルネックを発見するために、高負荷をシミュレートする。
- 大きなランダム木を生成し、標準的な操作を実行する。
- 時間の経過に伴ってメモリ使用量を監視する。
- 深さ優先走査の実行時間を測定する。
将来の欠陥を防ぐ 🛡️
予防が治療より良い。コーディング規範やアーキテクチャガイドラインを設けることで、複合構造の欠陥を導入する可能性が低くなる。
- コードレビュー:同僚レビューの際には、特に再帰的ロジックと参照の管理に注目する。
- ドキュメント:木の想定される深さとサイズを明確にドキュメント化する。
- 静的解析:再帰の深さに関する問題や循環参照を検出するためにツールを使用する。
- デザインパターン:コンポジットパターンを厳密に遵守する。階層を曖昧にするような方法で他の構造パターンと混ぜてはならない。
ベストプラクティスの要約 ✅
信頼性の高い複合構造を構築するには細部への注意が必要である。以下のチェックリストは、保守および開発における必須行動を要約している。
- 再帰メソッドには常に明確な終了条件を定義する。
- ノードを削除する際には参照をクリアすることを確認する。
- 走査の前に木構造を検証する。
- 非常に深い木の場合には再帰ではなく反復を使用する。
- マルチスレッド環境では、子リストへのアクセスを同期する。
- 空の状態や単一ノードの状態を徹底的にテストする。
- 開発および本番環境でメモリ使用量を監視する。
これらのガイドラインに従うことで、開発者は複合アーキテクチャの整合性を維持できる。デバッグはクラッシュの修正に焦点を当てるのではなく、階層を通じた制御フローの最適化に移行する。目標は、複雑な関係をモデル化できるほど柔軟でありながら、論理エラーを防げるほど厳密な構造を構築することである。
コンポジットパターンは抽象化のためのツールであることを思い出そう。複雑さを隠すものであり、新たな複雑さを導入するものではない。抽象化が漏れ出すと、デバッグプロセスが始まる。注意を払い、階層を清潔に保ち、すべてのノードが木の中で自分の位置を把握していることを確認しよう。