
डेटाबेस नॉर्मलाइजेशन का परिचय
डेटाबेस नॉर्मलाइजेशन एक मूलभूत तकनीक है जो संबंधित डेटाबेस डिजाइन में उपयोग की जाती है जिसका उद्देश्य डेटा को अतिरिक्त पुनरावृत्ति को कम करने, डेटा अखंडता सुनिश्चित करने और डेटा संचालन जैसे डेटा डालने, अपडेट करने या हटाने के दौरान विचलनों को रोकने के लिए व्यवस्थित करना है। एडगर एफ. कॉड ने 1970 के दशक में अपने संबंधित मॉडल के हिस्से के रूप में इसका विकास किया था, जिसमें डेटाबेस को तालिकाओं में संरचित करना और उनके बीच संबंधों को नॉर्मल फॉर्म्स नामक नियमों के आधार पर परिभाषित करना शामिल है। इन फॉर्म्स का पालन करने से डेटाबेस समय के साथ अधिक कुशल, स्केलेबल और रखरखाव के लिए आसान हो जाते हैं।
मूल रूप से, नॉर्मलाइजेशन डेटाबेस को एक संभावित अव्यवस्थित डेटा संग्रह से एक सुव्यवस्थित, तार्किक संरचना में बदल देता है। इसका उपयोग सरल एप्लिकेशन से लेकर जटिल एंटरप्राइज डेटाबेस तक के प्रणालियों में व्यापक रूप से किया जाता है, जिससे यह सुनिश्चित होता है कि डेटा ऐसे तरीके से संग्रहीत किया जाए जो अनावश्यक पुनरावृत्ति के बिना सटीक प्रश्नों और रिपोर्टिंग का समर्थन करे।
डेटाबेस नॉर्मलाइजेशन की मुख्य अवधारणाएं
नॉर्मलाइजेशन एक श्रृंखला के ‘नॉर्मल फॉर्म्स’ के माध्यम से आगे बढ़ता है, जिसमें प्रत्येक पिछले के आधार पर बनाया जाता है ताकि विशिष्ट प्रकार की डेटा पुनरावृत्ति और निर्भरता की समस्याओं का समाधान किया जा सके। यहां उदाहरणों के साथ समझाए गए मुख्य नॉर्मल फॉर्म्स हैं:
1. पहला सामान्य रूप (1NF)
- परिभाषा: एक तालिका 1NF में होती है यदि सभी मान परमाणु (अविभाज्य) हैं और कॉलम में कोई दोहराए गए समूह या ऐरे नहीं हैं। प्रत्येक पंक्ति-स्तंभ प्रतिच्छेदन में एक ही मान होना चाहिए, और प्रत्येक रिकॉर्ड अद्वितीय होना चाहिए।
- मुख्य नियम: अलग-अलग पंक्तियों या तालिकाओं के निर्माण द्वारा बहु-मान वाले गुणों को दूर करें।
- उदाहरण: ग्राहक आदेश के लिए एक तालिका पर विचार करें जिसमें एक कॉलम “आइटम” है जिसमें “सेब, केला, संतरा” है। 1NF प्राप्त करने के लिए, इसे अलग-अलग पंक्तियों में विभाजित करें: प्रत्येक आदेश के लिए एक आइटम के लिए एक पंक्ति। इससे ऐसी समस्याओं को रोका जा सकता है जैसे कि एक आइटम के अपडेट करने से पूरी सूची प्रभावित हो जाए।
2. दूसरा सामान्य रूप (2NF)
- परिभाषा: एक तालिका 2NF में होती है यदि यह 1NF में है और सभी गैर-की विशेषताएं पूर्ण रूप से प्राथमिक की के पूरे भाग पर फलनात्मक रूप से निर्भर हैं (आंशिक निर्भरता नहीं)।
- मुख्य नियम: उन डेटा के उपसमूहों को हटाएं जो कई पंक्तियों पर लागू होते हैं, उन्हें अलग तालिकाओं में रखें और विदेशी की के माध्यम से जोड़ें।
- उदाहरण: एक तालिका में OrderID (प्राथमिक की), CustomerID, CustomerName और Item कॉलम हैं, जहां CustomerName केवल CustomerID पर निर्भर है (आंशिक निर्भरता)। 2NF में नॉर्मलाइज करने के लिए, CustomerID और CustomerName को अलग Customers तालिका में ले जाएं, जहां Orders तालिका में CustomerID को विदेशी की के रूप में संदर्भित किया जाए।
3. तीसरा सामान्य रूप (3NF)
- परिभाषा: एक तालिका 3NF में होती है यदि यह 2NF में है और कोई अंतरित निर्भरता नहीं है (गैर-की विशेषताएं अन्य गैर-की विशेषताओं पर निर्भर नहीं हैं)।
- मुख्य नियम: सुनिश्चित करें कि सभी विशेषताएं प्राथमिक की पर सीधे निर्भर हों, किसी अन्य विशेषता के माध्यम से नहीं।
- उदाहरण: Employees तालिका में EmployeeID, DepartmentID और DepartmentLocation हैं, जहां DepartmentLocation DepartmentID पर निर्भर है (अंतरित)। एक Departments तालिका बनाकर नॉर्मलाइज करें जिसमें DepartmentID और DepartmentLocation हों, जिसे विदेशी की के माध्यम से वापस जोड़ा जाए।
उच्च सामान्य रूप
- बॉयस-कॉड सामान्य रूप (BCNF): 3NF का कठोर रूप, जहां प्रत्येक निर्धारक एक उम्मीदवार की होती है। यह ओवरलैपिंग उम्मीदवार की के प्रबंधन के लिए उपयोगी है।
- चौथा सामान्य रूप (4NF): बहु-मूल्यवान निर्भरताओं को संबोधित करता है, जिससे एक ही तालिका में स्वतंत्र बहु-मूल्यवान तथ्यों का निर्माण नहीं होता है।
- पांचवां सामान्य रूप (5NF): जॉइन निर्भरताओं के साथ निपटता है, जटिल संबंधों से अतिरेक को दूर करने के लिए तालिकाओं को और अधिक विभाजित करता है।
ये रूप संचयी हैं; उच्च स्तरों को प्राप्त करने के लिए निम्न स्तरों को पूरा करना आवश्यक है। जबकि 3NF अधिकांश व्यावहारिक डेटाबेस के लिए पर्याप्त होता है, जटिल डेटा संबंधों वाले परिदृश्यों में उच्च रूपों का उपयोग किया जाता है।
डेटाबेस सामान्यीकरण क्यों मुश्किल है
अपने लाभों के बावजूद, सामान्यीकरण एक मेहनत वाली और त्रुटि-प्रवण प्रक्रिया हो सकती है, विशेष रूप से बड़े या जटिल डेटा सेट के लिए। यहां विवरण है कि इसे अक्सर मुश्किल क्यों माना जाता है:
- निर्भरताओं का हस्तचालित विश्लेषण: कार्यात्मक, आंशिक और स्थानांतरित निर्भरताओं की पहचान करने के लिए डेटा संबंधों के गहन विश्लेषण की आवश्यकता होती है। इसमें आवश्यकताओं की समीक्षा करना, अतिरेक को निर्धारित करना और विचलनों का अनुमान लगाना शामिल है—इन कार्यों के लिए विशेषज्ञता और समय की आवश्यकता होती है।
- पुनरावृत्तिपूर्ण तालिका विभाजन: प्रत्येक सामान्य रूप को तालिकाओं के पुनर्गठन, कुंजियों को जोड़ने और संबंधों को पुनर्परिभाषित करने की आवश्यकता हो सकती है। उदाहरण के लिए, 1NF से 3NF में जाने के लिए तालिकाओं के बहुबार विभाजन की आवश्यकता हो सकती है, जिससे तालिकाओं और जॉइन्स की संख्या बढ़ सकती है, जिससे प्रश्नों की जटिलता बढ़ जाती है।
- सामान्यीकरण और प्रदर्शन का संतुलन: अत्यधिक सामान्यीकरण से अत्यधिक जॉइन्स का निर्माण हो सकता है, जिससे पढ़ने की प्रक्रिया धीमी हो जाती है। डिजाइनरों को आमतौर पर प्रदर्शन के लिए रणनीतिक रूप से असामान्यीकरण करना पड़ता है, जिससे निर्णय लेने का एक और स्तर जोड़ा जाता है।
- दस्तावेजीकरण और परीक्षण: परिवर्तनों का हस्ताक्षरित दस्तावेजीकरण और विचलनों के लिए परीक्षण करना (उदाहरण के लिए, ऐसे इन्सर्शन विचलन जहां डेटा को नल के बिना जोड़ा नहीं जा सकता) समय लेने वाला है। इस चरण में त्रुटियां डेटा असंगति के कारण हो सकती हैं।
- स्केलेबिलिटी की समस्याएं: विकसित हो रहे डेटाबेस के लिए, स्कीमा परिवर्तनों के बाद पुनर्सामान्यीकरण दोहराव वाला और जोखिम भरा होता है, जिससे उत्पादन प्रणालियों में व्यवधान हो सकता है।
सारांश के रूप में, सामान्यीकरण की मुश्किलता इसकी हस्तचालित और पुनरावृत्तिपूर्ण प्रकृति से उत्पन्न होती है, जिसमें डेटा अखंडता की समस्याओं से बचने के लिए निपुणता की आवश्यकता होती है, जबकि उपयोगकर्ता उपयोगिता बनाए रखी जाती है।
विजुअल पैराडाइम के DBModeler AI टूल द्वारा डेटाबेस सामान्यीकरण को सरल बनाने का तरीका
विजुअल पैराडाइम, डायग्रामिंग और डिजाइन टूल्स के एक प्रमुख प्रदाता, ने DBModeler AI लॉन्च किया है—एक आर्टिफिशियल इंटेलिजेंस प्रयोग करने वाला डेटाबेस डिजाइन टूल जो सामान्यीकरण प्रक्रिया को स्वचालित और सरल बनाता है। यह उपकरण कृत्रिम बुद्धिमत्ता का उपयोग करके प्राकृतिक भाषा वर्णनों को पूरी तरह से सामान्यीकृत डेटाबेस स्कीमा में बदलता है, जिससे हस्तचालित प्रयास कम होते हैं और विकास तेज होता है।
मुख्य विशेषताएं और कार्यप्रणाली
DBModeler AI की कार्यप्रणाली अंतरक्रियात्मक और मार्गदर्शित है, जिससे यह नवीनतम और विशेषज्ञों दोनों के लिए उपलब्ध होती है:
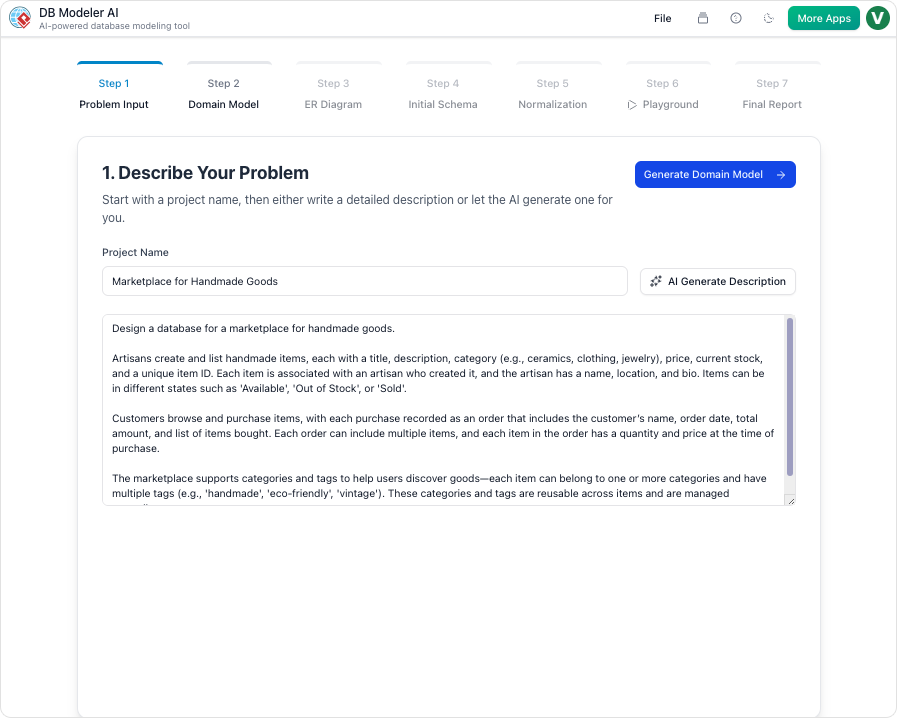
- साधारण अंग्रेजी में इनपुट आवश्यकताएं: प्राकृतिक भाषा में अपने डेटाबेस की आवश्यकताओं का वर्णन करके शुरुआत करें, उदाहरण के लिए, “ग्राहक आदेशों को ट्रैक करने के लिए एक प्रणाली, जिसमें उत्पाद, मात्रा और शिपिंग विवरण शामिल हैं।”
- डोमेन क्लास और ईआर डायग्राम उत्पन्न करें: AI तुरंत संपादन योग्य PlantUML डोमेन क्लास डायग्राम और विस्तृत एंटिटी-रिलेशनशिप (ईआर) डायग्राम बनाता है, जो एंटिटी, गुण और संबंधों को दृश्यमान करता है।
- स्वचालित सामान्यीकरण: यह स्कीमा को 1NF से 3NF तक क्रमबद्ध रूप से सामान्यीकृत करता है, प्रत्येक परिवर्तन के लिए चरण-दर-चरण तर्क और व्याख्या प्रदान करता है। इस शैक्षिक पहलू के कारण उपयोगकर्ता को यह समझने में मदद मिलती है कि अनावश्यकताओं या स्थानांतरित निर्भरताओं को दूर करने के कारण क्या है।
- एसक्यूएल उत्पादन और परीक्षण: पोस्टग्रेसक्वल के साथ संगत एसक्यूएल डीडीएल स्क्रिप्ट उत्पन्न करता है। एआई द्वारा उत्पन्न नमूना डेटा के साथ बिल्ट-इन लाइव एसक्यूएल प्लेग्राउंड के साथ, डेटाबेस परिवेश को सेट अप किए बिना प्रश्नों का तुरंत परीक्षण करने की अनुमति देता है।
- रियल-टाइम संपादन और निर्यात: डायग्राम, SQL या दस्तावेज़ीकरण को बारीकी से संपादित करें। साझा करने या एकीकरण के लिए सभी को PDF या JSON के रूप में निर्यात करें।
निर्भरता विश्लेषण और तालिका पुनर्गठन को स्वचालित करके, DBModeler AI बहुत सी बातों को दूर करता है, जिससे डिज़ाइनरों को बारीकी से बनाने पर ध्यान केंद्रित करने की अनुमति मिलती है, बजाय शुरुआत से शुरू करने के। यह दृश्य प्रतिक्रिया, AI-चालित दृष्टिकोण और त्वरित प्रोटोटाइपिंग प्रदान करके प्रक्रिया को सरल बनाता है, जिससे डिज़ाइन समय में काफी कमी आती है।
डेटाबेस सामान्यीकरण में DBModeler AI के उपयोग के मामले
DBModeler AI लचीला है और विभिन्न पेशेवरों और परिस्थितियों को संतुष्ट करता है:
- प्रोजेक्ट्स को शुरू करने वाले विकासकर्ता: साइड प्रोजेक्ट्स या प्रोटोटाइप्स के लिए, विकासकर्ता आवश्यकताओं से त्वरित रूप से सामान्यीकृत स्कीमा बना सकते हैं, SQL का परीक्षण कर सकते हैं और हाथ से डायग्राम बनाए बिना बार-बार बदलाव कर सकते हैं।
- छात्र और शिक्षार्थी: स्पष्टीकरण के साथ इंटरैक्टिव सामान्यीकरण एक शिक्षण उपकरण के रूप में काम करता है, जो छात्रों को हाथ से उदाहरणों के माध्यम से कार्यात्मक निर्भरता जैसी अवधारणाओं को समझने में मदद करता है।
- व्यापार आवश्यकताओं को अनुवाद करने वाले उत्पाद प्रबंधक: उच्च स्तरीय व्यापार आवश्यकताओं को तकनीकी ERD और स्कीमा में बदलें, जो रुचि रखने वाले पक्षों और तकनीकी टीमों के बीच के अंतर को दूर करता है।
- जटिलता का प्रबंधन करने वाले प्रणाली वार्ड: एंटरप्राइज सिस्टम के लिए जटिल डेटा मॉडल के प्रोटोटाइप बनाएं, संबंधों को दस्तावेज़ करें, और कार्यान्वयन से पहले सामान्यीकरण सुनिश्चित करें।
वास्तविक दुनिया के अनुप्रयोगों में, जैसे ई-कॉमर्स प्लेटफॉर्म या CRM प्रणालियों में, इस उपकरण के द्वारा विस्तार करने योग्य दक्ष डिज़ाइन सुनिश्चित होते हैं, जिससे लंबे समय तक रखरखाव लागत कम होती है।
सिफारिश: Visual Paradigm के DBModeler AI को क्यों चुनें
अगर आप डेटाबेस डिज़ाइन के साथ जुड़े हैं, तो मैं बहुत अच्छी तरह से सिफारिश करता हूंVisual Paradigm के DBModeler AI सामान्यीकरण को सुगम बनाने के लिए एक खेल बदलने वाला है। इसका AI-सहायता वाला दृष्टिकोण केवल समय बचाता है, बल्कि सटीकता और शिक्षा को भी बढ़ाता है, जिससे बोझिल कार्यों को प्रबंधित करना संभव हो जाता है। Visual Paradigm के प्लेटफॉर्म के माध्यम से उपलब्ध, यह दक्ष, सहयोगात्मक उपकरण चाहने वाली टीमों के लिए आदर्श है। अधिक जानकारी के लिए, उनकी आधिकारिक वेबसाइट पर जाएं ताकि विशेषताओं को जाना जा सके और शुरुआत की जा सके।
DBModeler AI क्या है?
DBModeler AI एक वेब-आधारित उपकरण है जोडेटाबेस आवश्यकताओं को पूरी तरह से सामान्यीकृत, उत्पादन-तैयार डेटाबेस स्कीमा में बदलता है। यह उपयोगकर्ताओं को एकके माध्यम से गुजरने में मार्गदर्शन करता है, जो और परीक्षण को जोड़ता है।
मुख्य विशेषताएं
| विशेषता | विवरण |
|---|---|
| AI-संचालित वास्तुकला | प्राकृतिक भाषा का उपयोग करके ऐप विचारों को विस्तृत तकनीकी आवश्यकताओं में बदलता है। |
| बहु-स्तरीय आरेखण | संपादन योग्य PlantUML डोमेन क्लास आरेख और ईआर आरेख उत्पन्न करता है। |
| चरणबद्ध सामान्यीकरण | आवर्तीता दूर करने के लिए व्याख्याओं के साथ 1NF, 2NF और 3NF तक योजनाओं को आगे बढ़ाता है। |
| लाइव एसक्यूएल प्लेग्राउंड | ब्राउज़र में एसक्यूएल क्लाइंट और एआई द्वारा उत्पन्न नमूना डेटा के साथ योजनाओं का तुरंत परीक्षण करता है। |
| पूर्ण नियंत्रण | आरेखों, एसक्यूएल और दस्तावेज़ीकरण में तत्काल संपादन की अनुमति देता है; पीडीएफ/जेसॉन में निर्यात करता है। |
चरण-दर-चरण कार्यप्रवाह
| चरण | क्रिया |
|---|---|
| 1. समस्या इनपुट | अपने एप्लिकेशन का सामान्य अंग्रेजी में वर्णन करें; एआई इसे तकनीकी आवश्यकताओं में विस्तारित करता है। |
| 2. डोमेन क्लास आरेख | संपादन योग्य प्लांटयूएमएल आरेख में उच्च स्तरीय वस्तुओं/लक्षणों को दृश्यमान करें। |
| 3. ईआर आरेख | डोमेन मॉडल को कुंजियों/संबंधों के साथ डेटाबेस-विशिष्ट ईआर आरेख में बदलें। |
| 4. प्रारंभिक योजना | ईआर आरेख को पोस्टग्रेसक्वल संगत एसक्यूएल डीडीएल बयानों में अनुवादित करें। |
| 5. स्मार्ट सामान्यीकरण | परिवर्तनों के लिए एआई-संचालित तर्कों के साथ 1NF से 3NF तक योजना को अनुकूलित करें। |
| 6. इंटरैक्टिव प्लेग्राउंड | वास्तविक डेटा के साथ ब्राउज़र में एसक्यूएल क्लाइंट में योजना के साथ प्रयोग करें। |
| 7. अंतिम रिपोर्ट और निर्यात | आरेख, दस्तावेज़ीकरण और एसक्यूएल स्क्रिप्ट को पीडीएफ/जेसॉन के रूप में निर्यात करें। |
लक्षित उपयोग केस
- विकासकर्ता: प्रोजेक्ट्स के लिए डेटाबेस लेयर को त्वरित रूप से बूटस्ट्रैप और प्रमाणीकरण करें।
- छात्र: इंटरैक्टिव तरीके से संबंधित मॉडलिंग और सामान्यीकरण सीखें।
- उत्पाद प्रबंधक: व्यावसायिक आवश्यकताओं को तकनीकी विवरण/ERD में बदलें।
- सिस्टम वार्डार: जटिल डेटा संबंधों को दृश्य रूप से प्रोटोटाइप और दस्तावेज़ करें।
बेहतर परिणाम के लिए टिप्स
- .
- सामान्यीकरण के दौरान AI व्याख्याओं का उपयोग सीखने के उपकरण के रूप में करें।
- उत्पादन निर्यात से पहले।
यह क्यों उभरता है
DBModeler AI स्वचालन और उपयोगकर्ता नियंत्रण को मिलाकर। यह विशेष रूप से उपयोगी है .
क्या आपको खोजने में मदद चाहिए आपकी आवश्यकताओं के लिए?